Next.js × ORM Practical Comparison: Experience the Differences Between Prisma / Drizzle / Kysely Running on Docker [Part 2]





This post is also available in 日本語.
Introduction
In Part 1, we compared three ORMs—Prisma, Drizzle ORM, and Kysely—for use in a Next.js App Router environment, focusing on type safety, migrations, Edge support, and compatibility with managed DBs.
👉 Part 1 is here:
In this article (Part 2), we’ll actually introduce and implement each ORM and compare them.
Approach of this article: actually run them and feel the differences
Build both PostgreSQL and MySQL on Docker
For each ORM, go through the full flow from defining migrations and creating tables to implementing APIs
Implement the same “user list retrieval API” with each ORM and compare
Get a practical feel for implementation ease, operational quirks, and type ergonomics
What you’ll gain from this article
- “Why do people say Prisma is convenient but heavy?”
- “I’ve heard about Drizzle recently, but is it really easy to use?”
- “How does Kysely’s type inference actually feel in practice?”
You’ll be able to understand these implementation-level differences and design philosophies—which you can’t really grasp without trying them—by experimenting with your own hands.
Target environment and assumptions
- Next.js 14 (App Router structure)
- Each ORM is used in an API Route (
app/api/users/route.ts) - PostgreSQL / MySQL are started locally via Docker and connected to
- We won’t touch front-end UI or SWR; we’ll focus on comparing the API layer
Recommended prior knowledge
- Have at least touched the structure of Next.js App Router
- Have used at least one ORM (e.g., Prisma)
- Basic Docker usage (enough to run
docker-compose up)
Let’s start with setting up the environment.
In the next chapter, we’ll prepare a Docker setup that can handle PostgreSQL and MySQL simultaneously and unify the .env.
The code implemented this time is stored in the following repository, so please refer to it as you follow along.
Environment setup (common preparation)
We’ll start by creating a Next.js project and launching Docker containers that can handle PostgreSQL and MySQL.
1. Create the project (in the orm-app/ directory)
npx create-next-app@latest orm-app \
--ts \
--app \
--tailwind \
--eslint \
--src-dir \
--import-alias "@/*"
Once the project is created, check that it can be started in development mode.
npm run dev
2. Create docker-compose.yml
We’ll spin up the following two DBs with Docker:
- PostgreSQL (for Prisma / Drizzle)
- MySQL (for Kysely)
version: '3.9'
services:
postgres:
image: postgres:15
restart: always
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: appdb
ports:
- '5432:5432'
volumes:
- pgdata:/var/lib/postgresql/data
mysql:
image: mysql:8
restart: always
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: appdb
MYSQL_USER: user
MYSQL_PASSWORD: password
ports:
- '3306:3306'
volumes:
- mysqldata:/var/lib/mysql
volumes:
pgdata:
mysqldata:
After creating the yaml file, start Docker.
docker-compose up -d
We’ll verify connectivity inside the Docker containers.
PostgreSQL
Connect to the container
docker exec -it <postgres container name> bash
Connect with the psql command
psql -U user -d appdb
MySQL
Connect to the container
docker exec -it <mysql container name> bash
Connect with the mysql command
mysql -u user -p
- Password:
password
Create .env.local for DB connections
# PostgreSQL for Prisma / Drizzle
POSTGRES_URL=postgresql://user:password@localhost:5432/appdb
# MySQL for Kysely
MYSQL_URL=mysql://user:password@localhost:3306/appdb
Check the directory structure
We’ve created a few files, so for reference here’s the current directory structure.
tree -I node_modules -I .git -I public -I .next --dirsfirst -a
.
├── src
│ └── app
│ ├── favicon.ico
│ ├── globals.css
│ ├── layout.tsx
│ └── page.tsx
├── .env.local
├── .gitignore
├── README.md
├── docker-compose.yml
├── eslint.config.mjs
├── next-env.d.ts
├── next.config.ts
├── package-lock.json
├── package.json
├── postcss.config.mjs
└── tsconfig.json
📁 src/app/
This is the routing directory dedicated to the Next.js App Router. The basic structure is as follows:
| File / Folder | Role |
|---|---|
page.tsx |
Route component corresponding to the top page (/) |
layout.tsx |
Global layout for pages (HTML structure, shared styles, etc.) |
globals.css |
Global CSS used across the app (often used with Tailwind) |
favicon.ico |
Icon displayed in the browser tab |
📄 .env.local
File for describing environment variables for local development (e.g., DATABASE_URL=...).
It’s excluded from Git and used to keep per-person settings.
📄 docker-compose.yml
Configuration for launching multiple Docker containers (DBs and app) at once.
For example, it likely defines development DBs such as MySQL and PostgreSQL.
📄 eslint.config.mjs
Configuration file for ESLint (static analysis tool, ESM format).
Used to unify code quality and syntax rules.
📄 next-env.d.ts
Type definition file automatically generated by Next.js.
Helps TypeScript correctly recognize the Next environment.
📄 next.config.ts
Next.js build configuration file (TypeScript).
For example, you can specify allowed image domains, redirects, module aliases, etc.
📄 package.json & package-lock.json
| File | Contents |
|---|---|
package.json |
Project dependencies, scripts, and meta information |
package-lock.json |
Locks and records the actual installed package versions (for reproducibility) |
📄 postcss.config.mjs
Configuration file for PostCSS.
If you’re using Tailwind CSS, you specify plugins here.
📄 tsconfig.json
TypeScript compiler configuration.
Controls path aliases (@/ etc.), strict mode, module format, and more.
Prisma: migrations and API implementation (PostgreSQL)
In this section, we’ll use Prisma to build a user data read API in a Next.js App Router environment. We’ll connect to PostgreSQL running on Docker and go through migrations, data seeding, API implementation, and type-safe development experience.
Prisma setup
Install dependencies and initialize
npm install prisma @prisma/client
npx prisma init
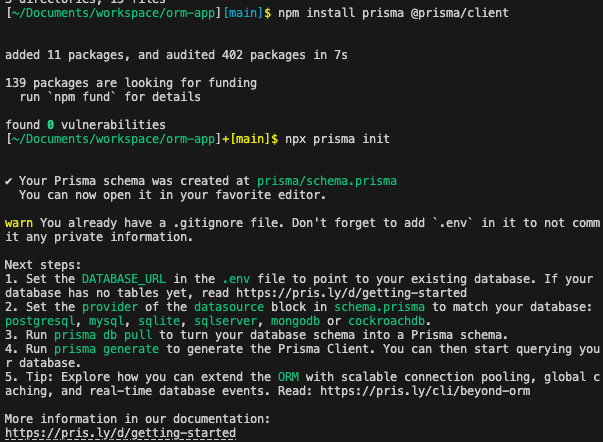
Generated structure:
prisma/
└── schema.prisma
.env
Connection settings
Add the following to .env.local and .env.
POSTGRES_URL=postgresql://user:password@localhost:5432/appdb
Define the Prisma schema
Define prisma/schema.prisma as follows:
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("POSTGRES_URL")
}
model User {
id Int @id @default(autoincrement())
name String
email String @unique
}
Run the migration
npx prisma migrate dev --name init
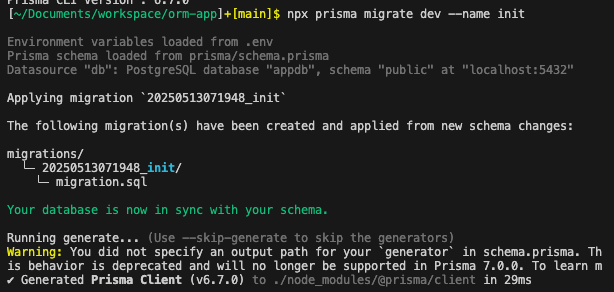
The table has been created.
You can check it with the following command:
npx prisma studio
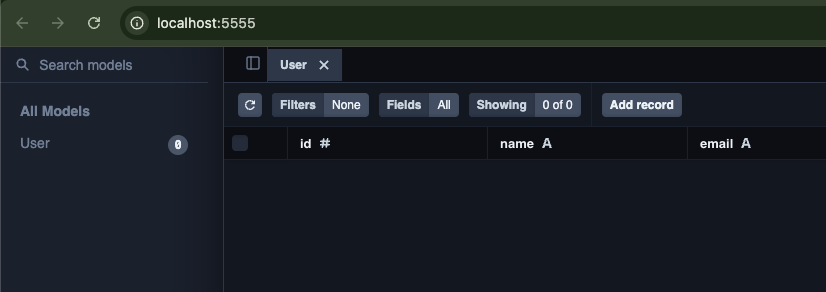
The columns we specified earlier exist, but there are no records yet.
Insert initial data (seed)
Create prisma/seed.ts:
const { PrismaClient } = require('@prisma/client')
const prisma = new PrismaClient()
async function main() {
await prisma.user.createMany({
data: [
{ name: 'Alice', email: 'alice@example.com' },
{ name: 'Bob', email: 'bob@example.com' },
{ name: 'Charlie', email: 'charlie@example.com' },
],
})
await prisma.$disconnect()
}
main().catch((e) => {
console.error(e)
process.exit(1)
})
Prepare to run it
npm install -D ts-node
Run
npx ts-node prisma/seed.ts
You can confirm that three records have been created.
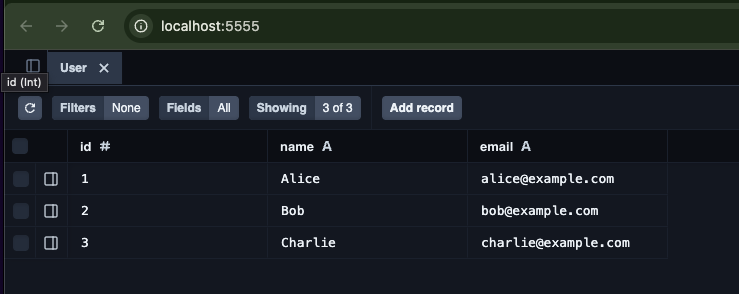
Implement the API
src/lib/prisma.ts
import { PrismaClient } from '@prisma/client'
const globalForPrisma = globalThis as unknown as {
prisma: PrismaClient | undefined
}
export const prisma = globalForPrisma.prisma ?? new PrismaClient()
if (process.env.NODE_ENV !== 'production') globalForPrisma.prisma = prisma
- Why write it this way?
In Next.js (especially with the App Router), modules may be re-executed every time they are hot-reloaded (HMR) during development.
Ifnew PrismaClient()is called each time, you may exceed Prisma’s connection limit (especially with managed DBs like PlanetScale or Supabase), causing connection errors.
| Line | Meaning and intent |
|---|---|
Use of globalThis |
Keep the prisma instance as a global variable for reuse |
globalForPrisma.prisma ?? new PrismaClient() |
Create a new instance on first run, reuse it thereafter |
if (process.env.NODE_ENV !== 'production') |
In production (single process), it’s fine to create it each time, so we avoid polluting the global scope |
This pattern is often used as a “singleton pattern (for development environments).”
src/app/api/prisma/users/route.ts
import { prisma } from '@/lib/prisma'
export async function GET() {
const users = await prisma.user.findMany()
return Response.json(users)
}
Explanation
app/api/prisma/users/route.tsis a Next.js App Router API route- Having this file automatically creates a
GET /api/prisma/usersendpoint
- Having this file automatically creates a
prisma.user.findMany()is the method to fetch all records of theUsermodel- The return type is
User[](auto-generated by Prisma)
- The return type is
Appeal of Prisma + App Router APIs
| Point | Description |
|---|---|
| Self-contained file | The API endpoint can be fully defined in just route.ts |
| Type safety | Arguments and return values of prisma.user.findMany() are typed |
| High reusability | Prisma Client is easy to reuse and share across multiple APIs |
| Prevents null/undefined issues | Prisma’s return values use appropriate union types |
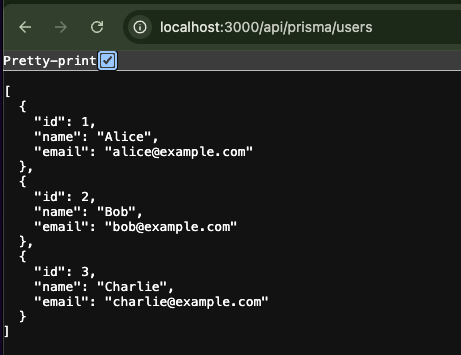
Check:
http://localhost:3000/api/prisma/users
If the users you created earlier are returned in the response, you’re good.
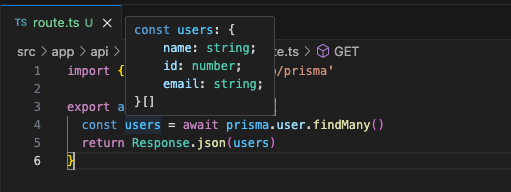
Concrete examples of type-safe development
The return type of await prisma.user.findMany() is explicitly known.
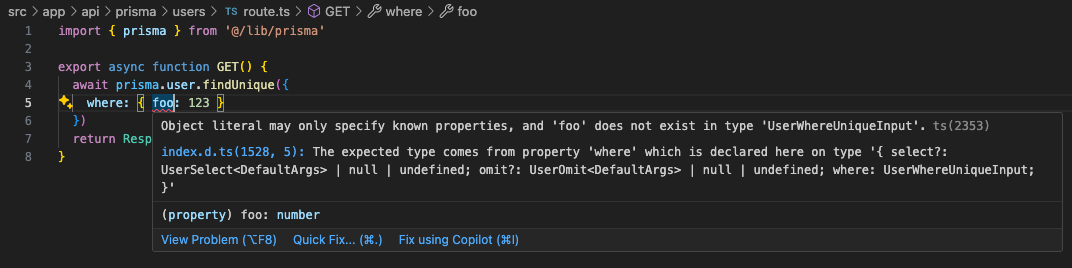
// Example of fetching a specific user
const user = await prisma.user.findUnique({
where: { id: 1 },
})
// Example of a type error (passing a non-existent field causes an error)
await prisma.user.findUnique({
where: { foo: 123 } // ❌ Type error
})
You can see in the editor that foo does not exist.
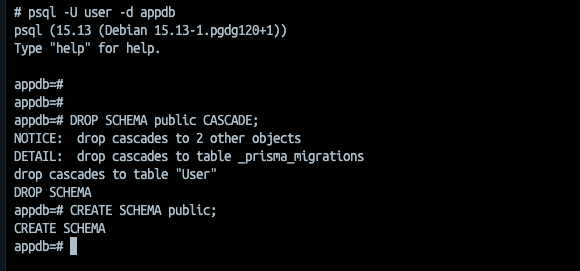
Delete data (cleanup)
Connect to the container, connect to the DB, then run the following commands:
DROP SCHEMA public CASCADE;
CREATE SCHEMA public;
Explanation
| Command | Meaning |
|---|---|
DROP SCHEMA public CASCADE; |
Drop the public schema (≈ all tables) |
CREATE SCHEMA public; |
Recreate an empty schema |
In this way, Prisma provides a fast development experience that balances reliable types with concise code.
In the next chapter, we’ll implement the same functionality using Drizzle ORM, which is characterized by its lightweight, SQL-like syntax, and compare.
Drizzle ORM: migrations and API implementation (PostgreSQL)
In this section, we’ll use Drizzle ORM to build a user data read API in a Next.js App Router environment. As with Prisma, we’ll connect to PostgreSQL running on Docker and go through schema definition, migrations, seeding, and API implementation in order.
Drizzle setup
Install dependencies
npm install drizzle-orm pg postgres
npm install -D drizzle-kit @types/pg
drizzle-orm: the ORM itself
pg,postgres: PostgreSQL drivers
drizzle-kit: CLI tool (for migrations)
Create drizzle.config.ts
Create drizzle.config.ts in the project root:
import { defineConfig } from 'drizzle-kit'
export default defineConfig({
dialect: "postgresql",
schema: './src/schema/drizzle-schema.ts',
out: './drizzle',
dbCredentials: {
url: process.env.POSTGRES_URL as string,
},
})
| Item | Description |
|---|---|
| DB type | Use PostgreSQL |
| Schema definition | Done in a TypeScript file (pgTable()) |
| Migration output | ./drizzle directory |
| Connection info | Use the connection string from the POSTGRES_URL env var |
3. Schema definition
With Drizzle ORM, you define table schemas directly in a TypeScript file. This keeps schema definitions and types in sync, giving you IDE completion and type checking for peace of mind.
Create src/schema/drizzle-schema.ts:
import { pgTable, serial, varchar } from 'drizzle-orm/pg-core'
export const users = pgTable('users', {
id: serial('id').primaryKey(),
name: varchar('name', { length: 255 }).notNull(),
email: varchar('email', { length: 255 }).notNull().unique(),
})
💡 Explanation:
pgTable()is a table definition function for PostgreSQL; the first argument is the table name, the second is an object describing the columns.serial()corresponds to PostgreSQL’sSERIALtype. It’s an auto-incrementing primary key.varchar()is a variable-length string type. You explicitly specify the length like{ length: 255 }..notNull()adds aNOT NULLconstraint..unique()adds a unique index.
With Drizzle, you can define schemas using TypeScript syntax, so you don’t need a separate DSL file like Prisma’s. This greatly reduces the risk of schema and code drifting apart.
Run the migration
Initialize (only the first time)
npx drizzle-kit generate
Apply to the DB
npx drizzle-kit push
Check with Drizzle Studio
As with Prisma, you can check tables via a GUI.
npx drizzle-kit studio
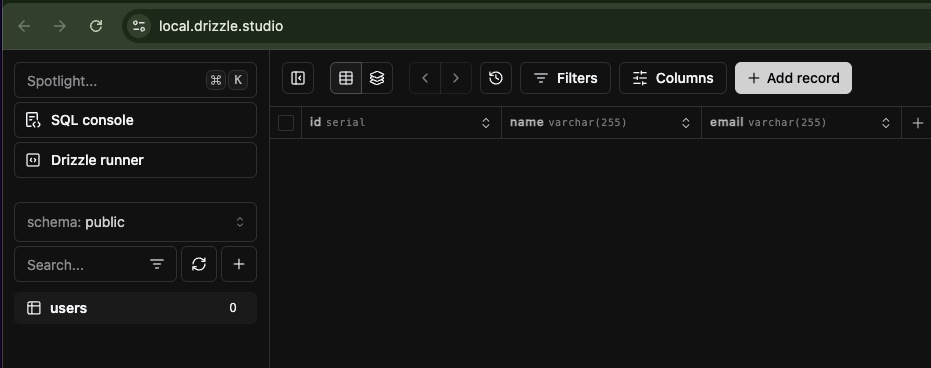
Access the URL shown in the console to confirm that the users table has been created.
Insert initial data (seed)
Similar to prisma/seed.ts, create scripts/drizzle-seed.ts:
import { drizzle } from 'drizzle-orm/node-postgres'
import { users } from '@/schema/drizzle-schema'
import { Client } from 'pg'
import 'dotenv/config'
const client = new Client({ connectionString: process.env.POSTGRES_URL })
await client.connect()
const db = drizzle(client)
await db.insert(users).values([
{ name: 'Alice', email: 'alice@example.com' },
{ name: 'Bob', email: 'bob@example.com' },
{ name: 'Charlie', email: 'charlie@example.com' },
])
await client.end()
Install dependencies
npm i dotenv
npm i -D tsx
How to run
npx tsx scripts/drizzle-seed.ts
Check in Drizzle Studio that three records have been created.
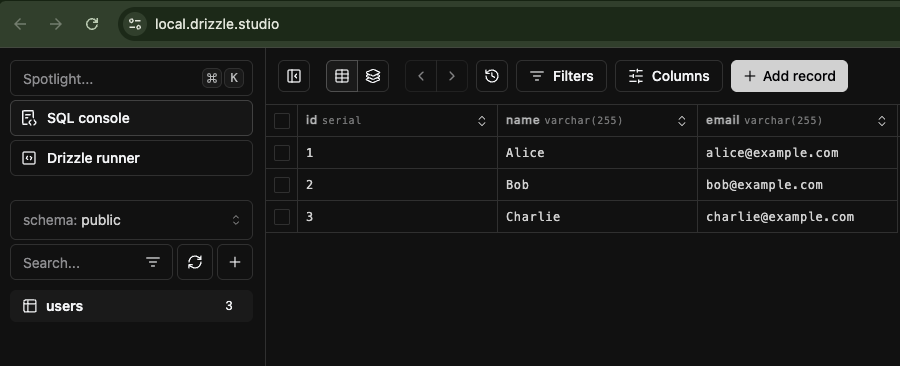
Implement the API
In this section, we’ll use Drizzle ORM to create an /api/drizzle/users API endpoint. This is an important implementation part for understanding how API Routes work in the Next.js App Router and how to build queries with Drizzle.
src/lib/drizzle.ts
import { drizzle } from 'drizzle-orm/node-postgres'
import { Client } from 'pg'
const client = new Client({ connectionString: process.env.POSTGRES_URL })
client.connect()
export const db = drizzle(client)
💡 Explanation:
- We use the
Clientfrom thepgpackage to connect to PostgreSQL. - Calling
drizzle(client)generates a type-safe query builder, and you can perform all operations viadb. - The connection is established once and reused within the app (you could also introduce a global cache).
src/app/api/drizzle/users/route.ts
import { db } from '@/lib/drizzle'
import { users } from '@/schema/drizzle-schema'
export async function GET() {
const result = await db.select().from(users)
return Response.json(result)
}
Explanation:
-
In the Next.js App Router, simply placing a
route.tsfile underapp/apiautomatically generates an API endpoint.- In this case,
/api/drizzle/usersis generated.
- In this case,
-
db.select().from(users)is Drizzle’s SQL DSL (Domain Specific Language) syntax:usersis the typed table defined withpgTable().select()selects all columns,.from()specifies the target table
-
Response.json(result)returns the fetched data as JSON. -
The return type is inferred based on
typeof users._.columns, preserving type safety.
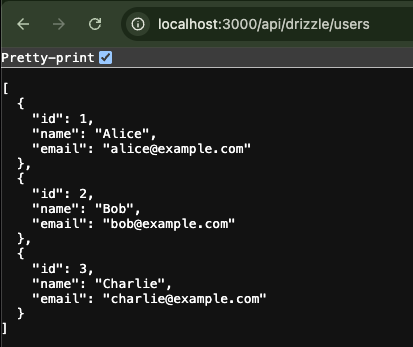
Check:
http://localhost:3000/api/drizzle/users
You should see three records in the response.
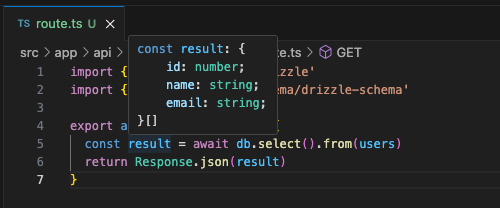
Concrete examples of type-safe development
As with Prisma, the return type of db.select().from(users) is explicitly known.
const result = await db.select().from(users).where(eq(users.id, 1))
// Example of a type error: specifying a non-existent column causes an error
await db.select({ foo: users.foo }).from(users) // ❌ Compile error

Delete data (cleanup)
DROP SCHEMA public CASCADE;
CREATE SCHEMA public;
Drizzle ORM strikes a good balance between SQL-like syntax and static typing, and it’s also well-suited for App Router + Edge Runtime setups. Next, we’ll move on to a comparative implementation using Kysely.
Kysely: App Router × Kysely (MySQL)
In this section, we’ll use Kysely to build a user data retrieval API in a Next.js App Router environment. Compared to Prisma and Drizzle, Kysely is known for its more “SQL-like” syntax and strong type inference. We’ll connect to MySQL (with services like PlanetScale in mind) and go through migrations, data seeding, and API implementation.
Kysely setup
Install packages
npm i kysely mysql2
Create the type definition file
With Kysely, you need to define types for each table yourself and pass them in.
import { Generated } from "kysely"
export interface UserTable {
id: Generated<number>
name: string
email: string
}
export interface Database {
users: UserTable
}
- What is
Generated<T>?- Can be omitted on
INSERT - Treated as present on
SELECT
- Can be omitted on
Initialize the Kysely client
import { Kysely, MysqlDialect } from 'kysely'
import { createPool } from 'mysql2'
import type { Database } from '@/types/db'
const dialect = new MysqlDialect({
pool: createPool({
database: 'appdb',
user: 'user',
password: 'password',
host: 'localhost',
port: 3306,
})
})
export const db = new Kysely<Database>({ dialect })
Migrations (run SQL manually)
Kysely does have a migration mechanism like Prisma and Drizzle, but it’s somewhat cumbersome to use.
So for this article, we’ll manage the schema by manually running SQL.
Here’s the SQL to create the users table:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
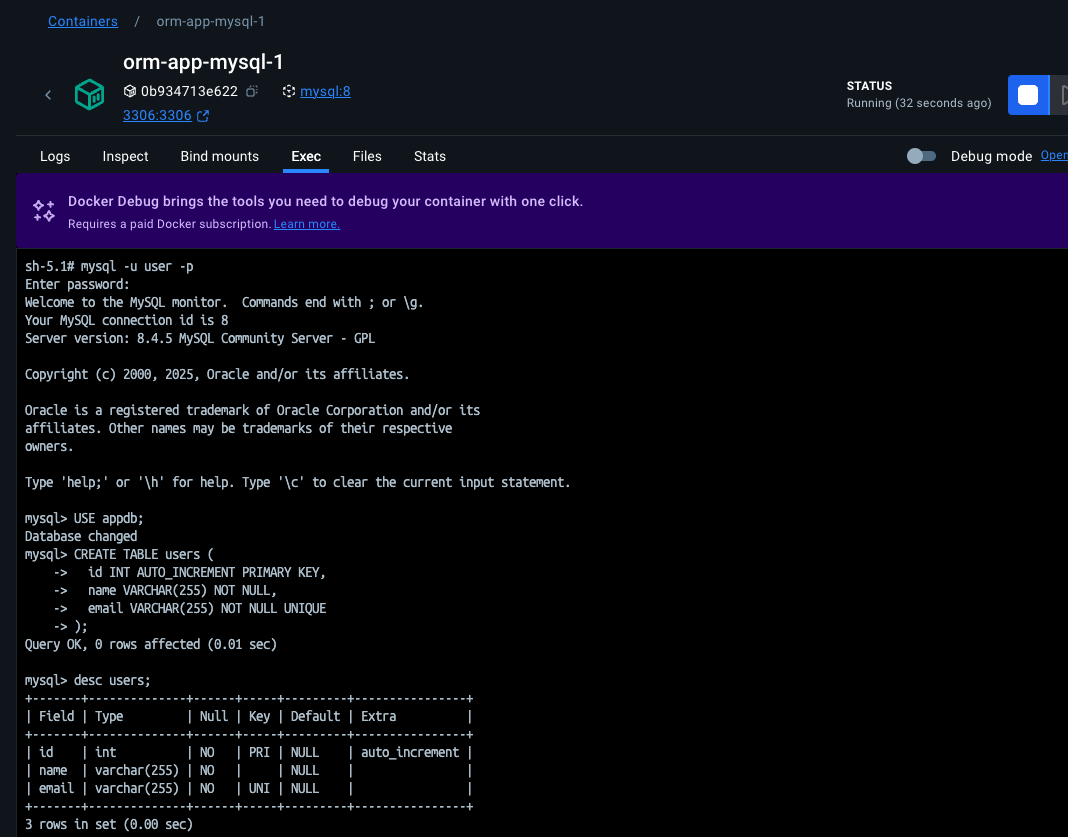
To run this SQL, the typical approach is to enter the MySQL container running on Docker and execute it there. You can do it like this:
# Enter the container
docker exec -it orm-comparison_mysql_1 bash
# Log into the MySQL shell
mysql -u user -p
# Password: password
# Select the DB
USE appdb;
# Run the CREATE TABLE statement above
This manual migration is a bit of work, but it gives you explicit control via SQL, and it works well with services like PlanetScale that impose constraints on schema changes.
You can either run it directly in PlanetScale or the Docker MySQL, or prepare it as an initialization script.
Insert initial data (seed)
import 'dotenv/config'
import { db } from '@/lib/kysely'
async function main() {
await db.insertInto('users').values([
{ name: 'Alice', email: 'alice@example.com' },
{ name: 'Bob', email: 'bob@example.com' },
{ name: 'Charlie', email: 'charlie@example.com' },
]).execute()
await db.destroy()
}
main().catch((e) => {
console.error(e)
process.exit(1)
}).finally(() => {
process.exit(0)
})
How to run:
npx tsx scripts/kysely-seed.ts
Implement the API (check after seeding)
Once the initial data has been inserted, you can implement an API endpoint like the following to verify data retrieval.
In the Next.js App Router, a route.ts file placed under app/api automatically generates an API endpoint. In this example, /api/kysely/users will handle GET requests.
Also, Kysely’s query syntax resembles SQL: .selectFrom('users').selectAll() corresponds to SELECT * FROM users.
import { db } from '@/lib/kysely'
export async function GET() {
const users = await db.selectFrom('users').selectAll().execute()
return Response.json(users)
}
http://localhost:3000/api/kysely/users
Accessing this endpoint should return the data for Alice, Bob, and Charlie that you inserted via the seed script, in JSON format.
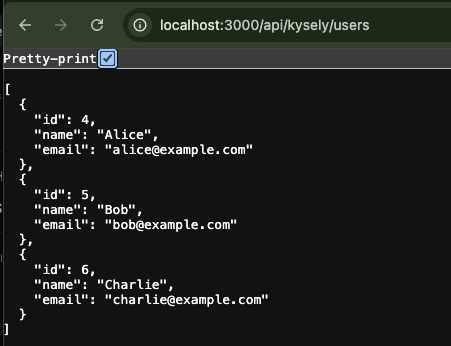
The IDs being 4–6 is just because the data was recreated; you don’t need to worry about it.
Type-safe development experience
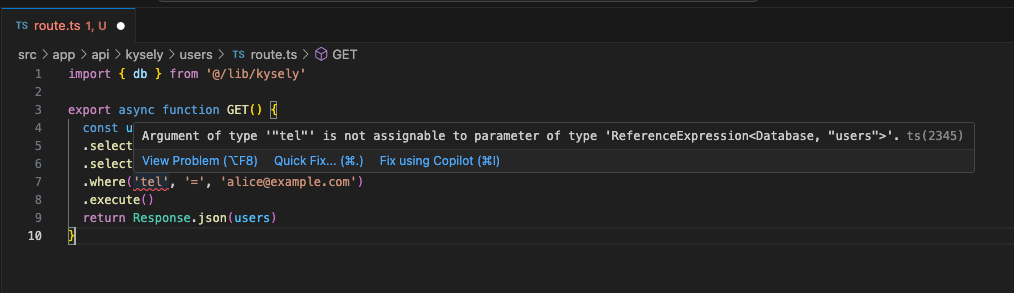
If you specify a non-existent table, a warning is shown.

const result = await db
.selectFrom('users')
.select(['id', 'name'])
.where('email', '=', 'alice@example.com')
.execute()
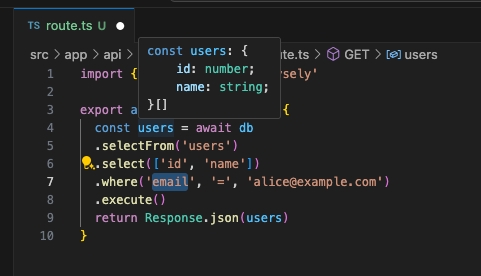
- Table and column names are not just literal strings; they’re subject to completion and type checking.
- At the
selectFrom().select()stage, column types are also inferred. - Typos or non-existent columns cause build errors.
If you try to build a where clause using a non-existent column, a warning is shown.
The return value is also recognized, so handling it in code is no problem.
Kysely is ideal for those who want to write flexible, SQL-like code, and it pairs well with PlanetScale (MySQL-based). Its type inference is particularly accurate, helping keep schema and code drift to a minimum.
With this, we’ve seen how to use and how it feels to work with Prisma, Drizzle, and Kysely in an App Router environment. Next time, we’ll summarize which ORM fits which use cases based on these findings.
Code comparison summary
| ORM | Ease of implementation | Migrations | Type safety | Edge support | Ease of connection initialization |
|---|---|---|---|---|---|
| Prisma | ◎ | ◎ | ◎ | △ | ◎ |
| Drizzle | ◎ | ○ | ◎ | ◎ | ◎ |
| Kysely | ○ | △ | ◎ | ◎ | ○ |
Conclusion
“Philosophical differences” that only become clear when you implement
In this article, we implemented and compared three ORMs—Prisma, Drizzle, and Kysely—on top of the Next.js App Router. At first glance they may seem to “do similar things,” but once you actually use them, you can clearly see big differences in design philosophy and development experience.
For example, Prisma offers a “comprehensive ORM experience centered on type safety,” Drizzle emphasizes “consistency by keeping everything, including migrations, in TypeScript,” and Kysely takes an approach of “staying as close to SQL as possible while still enjoying the benefits of types.”
ORMs should be chosen not by “which is superior” but by “how you want to use them”
As we’ve seen, what matters in ORM selection is not “number of features” or “speed,” but “what development philosophy you want to follow” and “whether it matches your team’s skill set.”
- Prisma’s abstraction suits those who prioritize “development speed” and “type safety” over extremely fine-grained SQL control or complex joins.
- Drizzle strongly meets the need for a simple, lightweight, TS-only setup.
- Kysely is for engineers who want to stay close to SQL while leveraging types to the fullest.
Configurations each ORM is good at / use cases they’re not suited for
| ORM | Strengths | Weak cases |
|---|---|---|
| Prisma | Apps where you want type-safe, rapid development | When you want fine-grained SQL control / using PlanetScale |
| Drizzle | Modern setups that should be lightweight, intuitive, and TS-based | When you need advanced relations or heavy abstraction |
| Kysely | When you want to stay close to SQL while maximizing type benefits | When you want migrations to be fully auto-managed |
Compared to the old Pages Router, the Next.js App Router structure has evolved toward “completing both APIs and components at the function level.” In that context, the key is to see which ORM can be integrated naturally and how to structure things so that it’s comfortable for your development team.
Ultimately, returning to “what you want to achieve” and “what kind of code you want to write” when choosing tools leads to healthier technical decisions.
The code implemented in this article is stored in the following repository, so please refer to it as you follow along.
Additional points when trying Supabase / PlanetScale (connections, limits, settings)
Additional points when trying Supabase / PlanetScale (connections, limits, settings)
In this comparison we targeted DBs running locally on Docker, but in real projects it’s increasingly common to use managed databases like Supabase or PlanetScale.
Here we’ll supplement how to connect ORMs to those services, their limitations, and configuration caveats you should keep in mind.
Supabase (PostgreSQL)
- Connection URL format
From the Supabase dashboard, go toDatabase > Connection PoolingorConnection string, and add something like the following to.env.local:
POSTGRES_URL=postgresql://postgres:your-password@db.xxxx.supabase.co:5432/postgres
-
SSL is required
Supabase connections have SSL enabled by default. Depending on the ORM, you may need to explicitly specifyssl: { rejectUnauthorized: false }in the connection options (for Kysely / TypeORM, etc.). -
Allowing remote connections
Right after creating a project, connections from some IPs may be restricted, so check the Supabase settings for an option to “allow external connections” as needed.
PlanetScale (MySQL)
-
Connections are per “branch”
In PlanetScale, connection URLs differ per branch such as “production” or “development.” You also need to generate passwords individually for each. -
Can’t directly use as
DATABASE_URL(Prisma)
PlanetScale doesn’t support some standard MySQL features (e.g., foreign key constraints, complex DDL). When using Prisma, you need to write something like the following in.envand setreferentialIntegrity = "prisma"inschema.prisma.
DATABASE_URL=mysql://<username>:<password>@<host>/<db>?sslaccept=strict
-
Edge-compatible library available
PlanetScale provides the@planetscale/databaselibrary, which allows you to connect to MySQL even infetch-based environments like the Next.js Edge Runtime or Cloudflare Workers (Prisma / TypeORM are not supported there). -
Migration constraints
PlanetScale adopts a workflow (GUI/CLI) based on “online schema changes,” which can clash with ORMs that expect to run migrations directly. Configurations where migrations are explicitly managed and separated, like with Drizzle or Kysely, are often preferred.
Thus, when using Supabase / PlanetScale in production or for testing, it’s important to understand not only the ORM settings but also the service-specific constraints and behavior.
By focusing not just on “whether the ORM supports it,” but also on “how that ORM deals with the DB’s limitations,” you can choose architectures that are less prone to trouble.
Questions about this article 📝
If you have any questions or feedback about the content, please feel free to contact us.
Go to inquiry formRelated Articles

Migrated from Next.js + Vercel to HonoX + Cloudflare Workers
2026/03/20
Test Strategy in the Next.js App Router Era: Development Confidence Backed by Jest, RTL, and Playwright
2025/04/22
Let's Build an Article Posting API with NestJS ─ Basics of Introducing Prisma and Implementing CRUD
2025/04/12
Thorough Comparison of the Best ORMs for the Next.js App Router: How to Choose Between Prisma / Drizzle / Kysely / TypeORM [Part 1]
2025/03/13